New BioMedIT Architecture
Categories:
Over 2024, we transitioned our federated platform and architecture to a more secure and streamlined model
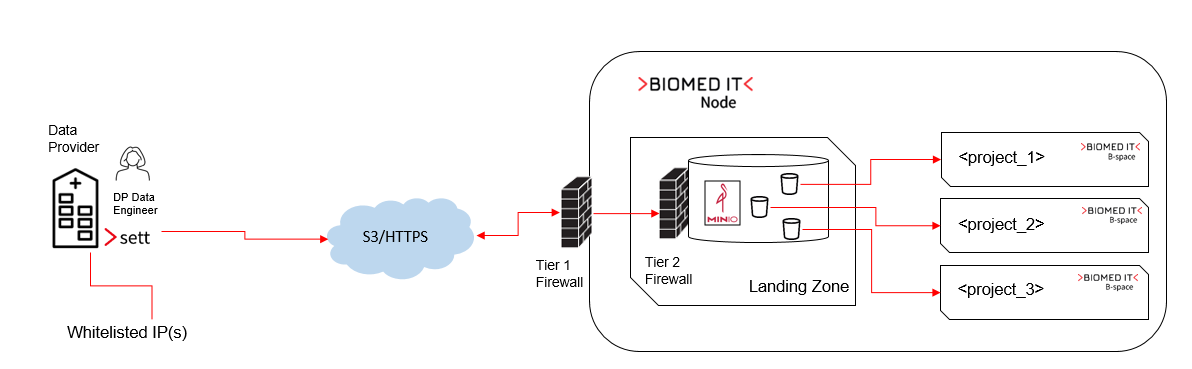
In its initial conception, BioMedIT linked every data provider for research projects to a single BioMedIT node, regardless of where the project was hosted. This snowflake design was chosen to minimize onboarding efforts for each data provider. Each provider had one landing zone, always at a designated node, where encrypted and signed data packages were sent—typically via Secure File Transfer Protocol (SFTP) from whitelisted IP addresses. From these landing zones, the data was internally transferred to the BioMedIT node hosting the project receiving the data.
As the network grew and evolved, our development and infrastructure teams designed a more streamlined architecture.
Key changes
1. A More secure transfer method: HTTPS vs. SFTP
HTTPS/S3 offers enhanced security compared to SFTP, leveraging robust encryption protocols and standard web ports to reduce potential vulnerabilities. Unlike SFTP, HTTPS simplifies network configurations, ensuring seamless integration with modern systems.
2. Simplified Data Providers onboarding
The onboarding process for new data providers is now more straightforward. HTTPS/S3 eliminates the need for complex SFTP configurations or the establishment of separate landing zones for each data provider. Any BioMedIT node hosting a project requiring data can onboard a provider with minimal effort.
3. Improved user onboarding
Granting permissions to new users to transfer data to a research project has been simplified significantly. With HTTPS, there is no longer a need to exchange SSH keys for authentication. Data Provider Managers can autonomously grant permissions to other users within their organization via the BioMedIT Portal, provided they perform the data transfer from the authorized institutional IP range.
4. Direct connections without transfer nodes
By enabling direct connections between Data Providers and BioMedIT nodes, the architecture no longer requires transfer nodes. This change not only simplifies the architecture but also reduces the number of data processors involved in the legal agreements. With fewer nodes acting as data processors, legal agreements are streamlined, saving time and effort for all involved parties.
How does the process looks like now?
Despite the architectural change, the data transfer process remains unchanged. Here is an overview of the workflow:
-
A user within the Data Provider’s Data Engineer group launches
sett(sett-guiorsett-cli) and authenticates using their SWITCH edu-ID. -
settretrieves the following information from the BioMedIT Portal:- The Data Engineer’s role.
- The list of approved data transfer requests for their organization.
- The necessary connection details to perform the transfer, including:
- URL of the S3 object store.
- S3 bucket name: This is where the data should be uploaded. The bucket
is named
<project_code>and was created by the sysadmins as part of the B-space setup. - Access credentials: These include the access key ID, secret key, and write-only STS credentials.
-
Using
sett, the Data Engineer selects the data transfer request, encrypts the data with the Data Manager’s public PGP key, and signs it with their own private PGP key. -
When S3 is selected as the destination,
settuploads the encrypted and compressed data package to the correct destination as a new object. The object name follows this format:
<project_code><YYYYMMDD>T<HHMMSS><optional suffix>.zip, which is the default ofsett’s output file naming scheme. -
Once the transfer is complete:
- The data package becomes available in the B-space.
- The Data Manager (data recipient) is notified.
- A log entry is created in the BioMedIT Portal.
-
In the B-space, the Data Manager decrypts the data using
sett. During this process, the sender’s signature and the checksum of all files are verified.